
There is coming, I think, a great change in how we discover things on the Internet. It is one which will play a major part in making the moving image central to knowledge and research, which is the goal that I am trying to pursue professionally. The great change will be brought about by speech-to-text technologies (also known as speech recognition).
Technologies that convert the spoken word into readable text have been around for a while now. Dictation tools such as those produced by Dragon do a fine job for the single voice which the software has been trained to recognise, and the new generation of smartphones now incorporates voice command technologies working on much the same principles. Speech-to-text systems are used in call centres, and by broadcasters to generate a rough transcript from which subtitles are then produced. But the great challenge has been how to apply speech-to-text to large-scale collection of speech-based audio and video, such as is held by broadcasters, archives and libraries.
Take the British Library for example. We have around one million speech recordings in our Sound Archive. They have catalogue records, so you can find out basic information about their contents, but providing more detailed descriptions, or even transcriptions, is enormously time-consuming, labour-intensive and slow – with the rate of production naturally falling way behind the rate of acquisition. On the video side of things, we have a rapidly growing collection of television news, amounting to 25,000 hours. Around half of this comes with subtitles captured as part of our off-air recording, so we can offer a pretty accurate, word-for-word (and word-searchable description) for those programmes. But for the other half – such as most 24-hour news channels – there are no subtitles. All you get is a one-line description taken from the Electronic Programme Guide saying something like “the latest news from around the world”, and that’s it. We need to open up those recordings to match the level of discovery we can offer for subtitled news programmes.
This isn’t just about opening up speech archives – it’s about levelling the playing field. The digitisation and digital production of text means that full-text searching across a vast corpus is now a reality, as we see with such sites as Project Gutenberg, Hathi Trust, Gallica, Trove, British Newspaper Archive, Papers Past, the Internet Archive and more. If video and sound are to be treated equally by libraries and archives, then that means they need to be discoverable to an equivalent level of depth, and for researchers to pursue subjects through books, manuscripts, newspapers, video and sound recordings on an equal footing. We need to know what those audiovisual records are saying.
Over the past couple of years speech-to-text technologies have developed to a stage where we are very close to achieving such a goal. University departments, broadcasters’ R&D divisions, the video industry, and the major web companies have all been in pursuit of this particular holy grail. It is no easy matter, as the human voice is a complex thing, and the huge variety of voices represented by any large video or sound archive will covers many different accents, languages, arrangements (i.e. multiple voices), instances of background noise, and so on. It’s interesting to see what’s driving much of this activity. It’s not an idealistic wish to push back the barriers of research. Go to the websites of the developers and service providers and again and again you’ll see the same thing – demonstrations of how good they are at reading Arabic. It is surveillance demands that are pushing this particular industry forwards.
Over the past year I have been leading a project at the British Library, entitled ‘Opening up Speech Archives’, which has looked at the application of speech-to-text technologies for research, particularly in the art and humanities. Funded by the Arts & Humanities Research Council, the project is not about assessing the best technical solutions. One thing you quickly learning when studying this field is that different applications work best in different situations. Instead the project has been looking at things from the researcher’s perspective, and asking some basic questions. How useful are the results to researchers? What are the methodological and interpretative issues involved? And how can speech-to-text technology be adopted in UK research in a form that is readily accessible and affordable?
For the project we have been interviewing researchers, either on a one-to-one basis, or in group sessions, and getting them to try out research topics on a variety of speech-to-text and related systems. We have been surveying the field, trying to get a good sense of the options and the possibilities. We have been in discussion with various vendors and service providers, and sending them test content. We are working on creating a demonstrator service. And we plan to publish our findings and share them with the research community at large.
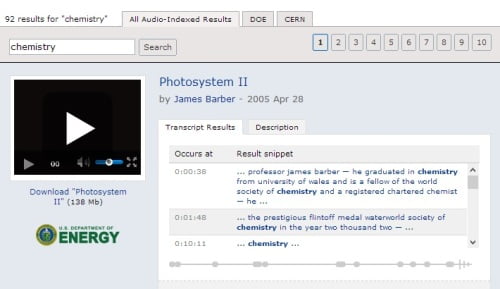
So, what’s out there? Well I have gathered together just a few examples of the interesting work going on out there. Microsoft have been working in this area for some time, with Microsoft Research having produced a system that they call MAVIS. Speech recognition systems tend to fall into two camps – either they are dictionary-based, so that they match the sounds played to them and then match these to wards in their dictionary, or they work from individual sounds elements, or phonemes. MAVIS is dictionary-based. It is now marketed as inCus by a company called GreenButton. You can try them system out at the ScienceCinema site, which is a collection of videos from the US Department of Energy and the European Organisation for Nuclear Research (CERN). Type in any term (pick a scientific one – ‘chemistry’ is a good example), and the results will be presented as a list of sentences in which your search term appears. Click on any one, and it takes you directly to that point in the video.
Demonstration video for Voxalead
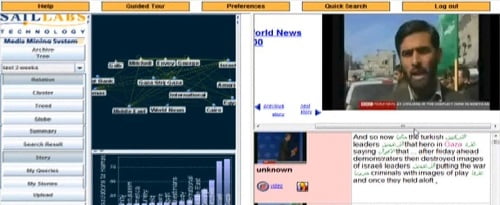
This enrichment of the search experience by generating subject terms, associations and other research tools out of the raw data generated by speech-to-text and other data sources is demonstrated by Voxalead. A product of French search engine Exalead, produced by Dassault Systèmes, this is a test service for searching video news online (Al Jazeera, BBC World Service, France 24, NBC, CBS etc). Type in any subject and it searches for programme descriptions, closed captions (subtitles) and audio tracks which it has indexed using speech-to-text. It presents these descriptions alongside related terms and people’s names that it has extracted from the records, linking these to other instances of those names. It takes the geographical records (i.e. place names) and positions these on a map. It also gives you a timeline showing when your search term is a its most frequent (search for ‘Mali’ for example and see how interest in the word has mushroomed over the past few weeks).
Voxalead is a really interesting demonstration of how these systems can work, though it’s only hosted as part of the labs site, and might disappear at any moment. That’s what happened to Google’s Gaudi service, which was available on the Google Labs site a few years ago, showing how you could search across videos of the first Obama election using speech-to-text, with instances of the word marked along the timeline of the video. This doesn’t mean Google has abandoned speech-to-text. Quite the opposite – the indications are that it is planning something major. There’s the almost casual mention in a recent Guardian piece on Amit Singhal, head of Google Search, that it “has been assiduously accumulating as much human voice recording as possible, in all the languages and dialects under the sun, in order to power its translation and voice recognition projects”, plus the news of the recruitment of Ray Kurzell, language processing expert, as director of engineering, with a brief to “to create technology that truly understands human language and its real meaning” and a blank cheque to enable him to do so, tend to point to something big, eventually.
Click on the automatic caption box on the right-hand side to see what I’m not saying about the British Library “brokaw snooze” service…
There are other indicators of big-ness. In January 2012 a US law was past which says that all TV broadcasts from the USA when published on the Web need to come with closed captions, to enable accessibility for all. this isn’t speech-to-text, but it is making a major tier of web video word-searchable, and where such a law can be passed in the USA, can Europe be far behind in its thinking? Already you can see on any YouTube video a new automatic captions service provided on the navigation bar. This provides an automatic transcription of what the person is saying. Often the results are quite comical, as you may see from the quite awful video of me above, which I use as an example only to spare the blushes of others.
Comical mis-transcriptions of speech-to-text are a joy. I particularly treasure one service transcribing “Chechnya” as “sexy eye”, and Voxalead reporting that French troops had liberated the city of Tim Buckley (Timbuktu). This Voxalead ‘transcription’ of some Al Jazeera news headlines from 4 February 2013 gives an idea of some of the delights to be found:
The Syrian president has accused Israel of trying to destabilize has country Bashar Al-Assad has told the Iranian foreign minister. The Serbian army and capable of handling any intervention. It comes as Israel’s defense minister, Ehud Barak hinted that Israeli involvement in an air strike near Damascus last week. British scientists are due to announce its results on whether the skeleton of King Richard the 3rd has been found buried under a cow pot. The first thing century ruler was immortalized in Shakespeare’s clay the hunchback you soak who had his 2 young nephews murdered archeologists think they find might lead to a real evaluation of the Monuc tension as a villain. You can find the latest on all those stories and more.
This must serve as a reminder that speech-to-text is not perfect, and probably never will be. Accuracy rates tend to range from 60-90%, depending on whether it is one person speaking to camera, or multiple voices. One reason that news programmes feature so heavily in such services is because the use of news presenters is ideal for them. Speech-to-text systems are not about perfect transcriptions in any case – they are about improving search. You have to concentrate on what they get right, and where that leads you.
We’re holding a conference at the British Library on 8 February, entitled Opening up Speech Archives, where we will be discussing some of these services, and trying to assess how best they can benefit academic research. There will be speakers from BBC R&D, the Netherlands Institute for Sound & Vision, Oxford University, Cambridge Imaging Systems, the BUFVC and Autonomy. The event is full, but we will be publishing conclusions from the conference and the project overall on the British Library website hopefully by the end of February – certainly not long after. You’ll also be able to follow me – and other participants – on Twitter, through the hash tag #ousa2013.
Will all of this change how we discover things on the Internet in a truly significant way? I think it will. It’s not just that we’ll be able to uncover huge amounts of speech-based content (assuming that these systems become affordable on a mass scale). It’s how these records will be discoverable alongside all the other text-based records in libraries, archives, and the Web, that is going to be so revolutionary. We will have two levels of discovery – the basic level (a catalogue description, essentially), and the full-text level, in which every word in a document, of whatever medium, is discoverable. And from the words our systems we then build, or enable us to build, further associations by extracting key terms – subjects, names, locations, dates, time periods, concepts – which can then create links to other files, and be used for themselves to visualise data, to map associations, to learn new things about the familiar and to discover the hidden and unsuspected.
Such interconnected systems won’t just make us able to do what we do now, which is to search in a rather linear way (query > listing > answer), but will immerse us in data, radiating out from whatever it is we are thinking about. We will have to see things differently, ask new questions, discover things we hadn’t even realised we were looking for. And the moving image will be central to all this. Of course moving images aren’t all about speech (there’s a whole other long post to be written about image recognition systems), but words give moving images their specificity, and they connect the medium to the traditional modes of discovering knowledge, which is to say through books and manuscripts. 120 years or so after motion picture film was established, we might finally be in a position to start learning from it.
Links:
- There’s background information on the Opening up Speech Archives project on my British Library Moving Image blog
- The ‘Speech to Text’ group on the Playback network for sound enthusiasts describes several of the systems out there
- ‘Google and the future of Search’, an article from The Guardian on 19 January 2013, gives some idea of the extent of its future ambitions
- See where speech-to-text comes on this graph of ‘Gartner’s Hype Cycle for Emerging Technologies‘, alongside natural-language question answering, automatic content recognition, 3D bioprinting and mobile robots
- Japanese mobile network NDD Docomo is to introduce a service in which users can speak in one language down the phone and the listener can hear the results in another language, thanks to a mixture of speech recognition and language software. Is this the way new wars might begin…?
- The talk I gave at the Opening up Speech Archives conference, adapted from this blog post, is available here: https://lukemckernan.com/wp-content/uploads/speechtotext.pdf
I am interested in how documents, artifacts, records and “things” such as you refer to can be *indexed*: that is sound recordings and visual images, where *indexed* means the listing of detailed references to particular subjects within the body of the work as in the established discipline of text indexing.
Because audio and video recordings move forward in time I think that their indexed references have to be in commonly understood time markings (seconds, minutes, hours or combinations of them).
Do the developing schemes you mention allow for them indexing themselves in any way – and would they use an Indexer to bring their indexes up to professional standards?
Indexed means that the files put through any such process are time-stamped (i.e. time code), so the desired word, phrase of phoneme (depending on your system) is identifiable as having occurred at a particular in the duration of the sound or video file. The results can be presented in various ways, but often it’s by having a navigation bar (such as you get at the bottom of a YouTube video) with markers along the bar indicating those points where the word you are searching for occurs.
Such systems do their own indexing. The human input comes in supplying the words or phonemes that the system needs to understand, say through a dictionary. It is possible to ‘train’ such systems further by adding additional text sources. For example, some of the news-based systems pick up extra intelligence about the news agenda through other web news sources produced on the same day on the same topic.
So it’s not indexing in the traditional, human sense. it’s a machine trained to recognise a set of words, finding these within a set of data fed into it, and relaying the results matched to particular points in the timeline of the video. You could get a human to improve records, saying by correcting errors in the transcription, but on the mass scale that I think will happen this just wouldn’t be practical.
As a profession, librarians are doomed.
Very interesting blog Luke, a good read for so many worrying av-archivists. The BBC World Service Archive is a fantastic example of new annotation techniques reinforcing each other (says one of the users 🙂 ). Keep an eye on the FIAT/IFTA website, probably next week we’ll publish the official announcement for our MMC Seminar in Hilversum, May 16-17th, featuring (among others) the *conclusions* of the World Service project, and experiences from a broadcaster’s archive where speech-to-text is in day-by-day use as we speak (no pun intended). Which brings me to a question that I was often asked: what about s-t-t for smaller languages? Will it ever work for Slovenian or Danish for example?
Thanks Brecht. It is a really interesting area which I genuinely believe will make a huge impact on how we discover things in the future. Right now it’s the preserve of governments and the military, but all of the elements are coming into place to see it expand much further. I’ll look out for the FIAT/IFTA announcement, certainly.
Though I’ve not seen a S2T system for ‘smaller’ languages yet, there’s no reason why not if the demand’s there. Perhaps the Danish radio digitisation project LARM is doing so – it’s hinted at here: http://www.larm-archive.org/about-larm/.
Hi Luke, thanks for the heads up.
I realise that initial research, for obvious financial and surveillance reasons, concentrated on keyword monitoring as a tool to vet all forms of text data transmission…by putting the word ‘bomb’ in this comment, it’s bound to flag up somewhere in the system. A need was then identified to close the loophole as terrorists changed tactics, with skype, iphones etc. and the often overlooked re-invented method of steganography, which I demonstrated a while back on my own website (now shut down), by inverting the process and hiding high resolution photos in audio field recordings.
The point I’m eventually getting round to is that good progress has been made by the security services, and keyword flagging by now should be down to a fine art, but they are working primarily with digital data, whereas, I should imagine, the bulk of archived material of interest to the public consumer is analogue, waiting to be digitized. Unfortunately this process is perhaps the most time-consuming and costly, and if incorrectly transposed ends up worthless. I originally tweeted to you that I had a question relating to metadata tagging – the reason being that speech recognition is all well and good, but is useless where no speech is present, and given that much of the modern video and audio we scientific orientated listeners listen to, relate to non-speech media such as nature sounds, location ambience, general field recordings etc., most of which has scientific value and would benefit from being searchable; so merely concentrating on keyword flagging or whatever you call it, will fall short of producing a comprehensive archive search tool.
So back on track (excuse the pun); the idea you mentioned about cloud tagging is likely to be of the most use, given that I was going to ask the question – will this mean the demise of, and waste of several years metadata tagging, as commonly used in audio file managers such as Helium Music Manager which tag file headers in most audio file formats, or the more specific broadcast industry BWF tagging software? If the transposed archive media were to be reliably cloud tagged the search tools would not have to be redesigned, as we already have them; they would search quicker, without having to read the complete file, which incidentally would be a mammoth task with some of the other methods mentioned in your blog, as video files are unwieldy gigabyte beasts to handle; and finally the search results would be accurate. As most of us know, the problems of searching media increases as the amount of data increases – eg: most Google searches will find too much material – in fact you need a search of a search of a search to produce something useful; someone said only look at the first page of results, the rest is rubbish.
…and finally…… my speech activated satnav still cannot understand my broad Norfolk dialect …that damn woomun nevvuh larns nothin!
Best regards
Hi Lawrence (I presume),
I don’t see why the rise in speech recognition and associated tagging should render metadata tagging for non-verbal sounds an irrelevance. If the metadata is there, the engines will harvest it up, and the digital files will be re-applied wherever there is an audience for them. A full-on commercial system Autonomy offers not just speech-to-text, subtitles capture and other word-based tools, but melody recognition as well, so I don’t see why audio files described in a consistent manner couldn’t be included in such a model. But audio file standards are not my specialism.
I would’t entirely agree with the idea of tagging being of most use when it comes to speech recognition – it depends on your source material. Those, such as the BBC World Service Prototype, who have gone down the tagging route have done so because they are working with diverse material where transcriptions are inevitably of a low standard. Others, generally working with news content, have gone down the full(-ish) transcription route with extracted terms on top of that. I prefer the latter (as a news researcher), but appreciate the pragmatism of the former.
I am intrigued by your assertion that the bulk of archived material likely to be of interest to the public consumer is in analogue form, waiting to be digitised. Is this true? There are vast archives out there awaiting digitisation, of course, but there is now a huge amount of archive content that is born digital (using ‘archive in its broadest sense – so YouTube is an archive). Does one outweigh the other, and if so which? And which of the two is the majority of people most interested in? I shall have to look into this…
Perhaps I should expand on my previous reply.
Given that the majority of media produced is likely to remain in the digital format for the foreseeable future, (although there are signs of a possible change in file storage devices and hence file formats on the horizon, see http://n.pr/10wouOR ), and my previous inference that anything is possible with digital media, the limits bounded only by the ability and flair of the software programmer or recording artist; I think this area is readily covered.
But therein lies a problem, and I do have issues with this where it involves archived digital material and its subsequent release for research; particularly with the search methods proposed based on content from within the media itself; as there is no provenance, and could for the want of better words be ‘photoshopped’, ‘synthesized’ or whatever you wish to call it, and the library archive and consumer will never be the wiser. It is essential therefore to retain some form of tagging to provide provenance. Some will say, well manipulation happened in the analogue age – yes it’s true to a lesser degree, but was difficult to achieve without leaving some trace or other: however with digital media it’s a different story, it’s difficult sorting fact from fiction and there are no tell-tale signs.
There was mention of YouTube, Vimeo etc as the modern media archive, that’s good, but user beware. A YouTube search for ‘UFO’ (yes there are serious researchers in that field) will provide a useful indication of how rife digital manipulation now is, with an ever increasing trend, possibly matching that of the advancement in consumer grade hardware and software. So how on earth do we discriminate between what’s true and what’s fake with digital media? Unfortunately, based on content alone, it’s impossible to detect fake content without the aforementioned file provenance.
There is certainly a market for improved content-based search methods mentioned, but I think mainly for entertainment purposes; I have reservations when used for other research, which is the area of use where it would prove the most beneficial, were it not for the problems referred.
Your area of expertise mentioned is the one to be in, I believe the next generation of recorders will all but eliminate the need for separate audio, photographic and video recording systems, particularly now that the HDSLR camera manufacturers are giving the video manufacturers a run for their money and all have recognised the need for professional audio recording capabilities in response to past criticism. We are already witnessing the single photo/video package within the HDSLR camera, and current video editing software has in turn acknowledged the need for greater audio editing capabilities, so all-in-all, apart from a few restrictions and high cost, we’re just about there with a single comprehensive media camera package and editing suite, into which may be developed a unified file tagging system (I wish).
Expanding on my comment about the bulk of archived material of interest being analogue: my thought is that your ‘born digital’ termed archive is already accessible and most probably already
satisfying interest on an ongoing basis, leaving a vast wealth of archived analogue material hidden from view, held on trust for the benefit of all, but never actually seen or heard: once digitized there will be no excuse for non-accessibility by all and will be of the greatest interest.
Finally; you may already be aware of my views relating to archives in general and the manner in which media has, and in many cases still is, subject to restricted access; but freely available to a priviledged few in order to make money from sales of books, DVDs etc., but I am pleased to see a rapid change of late as these barriers are removed. It just remains for archives to redirect more of their resources into the digitization of existing analogue media, enabling its free internet access; otherwise they risk becoming ridiculed as some are now, by wasting limited resources in producing lists and dead links which provide but little useful information. I think it imperative that prior to the introduction of sophisticated search engines outlined; that resources be first directed to the digitization of this existing media, to avoid the Google search syndrome with its pages of rubish and dead links, which inevitably leads to frustration for the user. Archives must realise that they are dealing with a Worldwide audience requiring access in their own respective timezones 24 hours a day, the majority are not interested in the opening and closing hours or the location of the nearest tube or bus station, they require immediate internet access to the specific digital file identified by an accurate search engine.
Best regards
Provenance metadata is an essential element of archiving. Its absence is sites such as YouTube is why they cannot truly qualify as archives. The vast number of online videos which give no indication (or else false indication) of their antecedents is a real worry.
Most archives would digitise everything is they could. Few have the resources to begin to tackle even the smallest fraction of their ambitions. Copyright obligations are a further barrier to ‘free’ internet access.